Validating Voice-Input Capture in Headless CI with PulseAudio and Chrome SpeechRecognition
How we validate Chrome extension microphone initialization and listening-state transitions with manifest permission auditing, explicit FAIL vs SKIP semantics, and a virtual microphone in CI.
Testing voice input in a Chrome extension is a systems problem, not just a UI problem. For a single microphone click to work, the extension manifest, browser permission flow, Chrome's speech stack, and the OS audio subsystem all need to line up. A DOM assertion can tell you that the button exists. It cannot tell you that the voice path is actually usable.
This post documents the failure mode we hit in VibeBrowser, why our original CI test produced a false positive, and the three-layer test strategy we now use to catch it: a manifest audit, strict failure semantics, and a real virtual microphone in CI.
That matters even more once coding agents are part of the development loop. When an agent writes code, tests are the most important feedback channel it gets about the real system. A weak test does not just miss a regression; it teaches the agent the wrong proxy for success. In our case, that meant CI could stay green while the actual voice path was broken.
The bug that CI did not catch
VibeBrowser uses webkitSpeechRecognition for voice input. The user clicks a microphone button, Chrome captures audio, and the recognized text is inserted into the prompt composer.
What was not simple: at some point the audioCapture permission went missing from manifest.json. In an extension context, Chrome checks that manifest permission before allowing device-audio capture. When it was missing, our getUserMedia({ audio: true }) probe failed with NotAllowedError, and users immediately saw "Microphone access denied" after clicking the voice button.
Our CI voice test was still passing while production was broken.
Why the original test produced a false sense of safety
The original test had two problems, but they mattered in different ways.
Problem 1: the success criteria were wrong.
The relevant test code looked like this:
const hasMicError = pageText.includes('Microphone access denied') ||
pageText.includes('Error:');
if (hasMicError) {
harness.log('Voice input not available in CI environment - SKIP');
passed.voice = true; // ← treating any error as a pass
}
"Microphone access denied" was in the known-error list, and hitting a known error set passed.voice = true. That made a missing manifest permission invisible. A real regression was being treated as a harmless CI limitation.
Problem 2: the environment setup only covered part of the audio path.
We launched Chrome with:
--use-fake-device-for-media-stream
--use-fake-ui-for-media-stream
These flags are standard for media tests. They auto-accept the browser media prompt and provide a synthetic stream for getUserMedia.
The fake media flags helped with getUserMedia, but they did not provide an OS-level audio device for Chrome's internal SpeechRecognition capturer. That distinction became important once we fixed the PASS/FAIL logic: the test could now correctly fail permission regressions, but it still could not validate that the real speech path initialized in headless CI.
Fix part 1: explicit PASS, FAIL, and environment SKIP classification
The first fix was rewriting the harness logic so PASS, FAIL, and environment SKIP were classified separately:
const isPermissionDeniedError =
lowerObservedError.includes('microphone access denied') ||
lowerObservedError.includes('not-allowed');
const isEnvironmentLimitationError =
lowerObservedError.includes('network error') ||
lowerObservedError.includes('not supported in this browser') ||
lowerObservedError.includes('no microphone found') ||
lowerObservedError.includes('no speech detected');
if (afterPressed === 'true' && hasListening && !observedErrorText) {
// Genuine success: button is active, listening text visible, no errors
passed.voice = true;
} else if (isPermissionDeniedError) {
// Hard FAIL: manifest permission regression
harness.log(`FAIL: Permission-denied regression: "${observedErrorText}"`);
} else if (isEnvironmentLimitationError) {
// SKIP: real CI constraint, not a code bug
harness.log(`SKIP: Environment limitation: "${observedErrorText}"`);
passed.voice = true;
} else {
// FAIL: unknown problem, must investigate
harness.log(`FAIL: Unknown voice error: "${observedErrorText}"`);
}
This restores the invariant: permission errors are always a FAIL. In this harness, environment SKIPs are still non-failing, but permission-denied and unknown errors are not allowed to collapse into that bucket. The test now catches any future regression where the audioCapture permission disappears from the manifest.
Fix part 2: static manifest permission audit
We added a second defence layer: a static analysis script that runs as part of the lint stage.
// scripts/audit-manifest-permissions.js
const REQUIRED_PERMISSIONS = {
audioCapture: [/webkitSpeechRecognition/, /getUserMedia.*audio/],
clipboardRead: [/clipboard\.readText/],
tabs: [/chrome\.tabs\./],
// ...
};
for (const [permission, patterns] of Object.entries(REQUIRED_PERMISSIONS)) {
const usedInCode = patterns.some(p => sourceFiles.some(f => p.test(f)));
const declaredInManifest = manifest.permissions.includes(permission);
if (usedInCode && !declaredInManifest) {
console.error(`MISSING: "${permission}" used in code but not in manifest`);
process.exit(1);
}
}
This runs on every push before the extension is even built. If a developer adds a new Chrome API without declaring the corresponding permission, CI fails at the lint step.
The deeper problem: voice still SKIPs in CI
With the strict logic in place, the audio-capture error from webkitSpeechRecognition now caused a SKIP instead of a false PASS. That was better — but it meant the actual voice user experience (button toggle, listening state, no crashes) was still never validated in CI.
The root cause is architectural. --use-fake-device-for-media-stream only fakes the WebRTC pipeline. Chrome's SpeechRecognition uses a different internal audio capturer that talks directly to the OS audio subsystem. In a Docker container with only libasound2 installed (the ALSA runtime library but no device), Chrome fires:
onerror({ error: "audio-capture" })
...before the speech pipeline even tries to reach Google's servers. There is no audio device, so there is nothing to capture from.
At that point, the only honest way to test the path was to give Chrome a real virtual audio device.
Why we did not stop at a JavaScript mock
We could have mocked SpeechRecognition in the page and asserted that the UI moved into the listening state. That would have been a valid component-level test, but it would not have caught the class of bug that actually broke production.
| Approach | What it validates | What it misses |
|---|---|---|
JS mock of SpeechRecognition |
Our UI state machine and wrapper logic | Manifest permissions, Chrome audio initialization, real browser error modes |
| PulseAudio virtual microphone | UI state, browser speech startup, OS audio boundary | Transcript quality and actual spoken-word recognition |
For this path, we cared more about browser-boundary regressions than transcript accuracy. The risk was not that Chrome would mishear a sentence in CI. The risk was that the feature would fail before it even entered the listening state.
Fix part 3: PulseAudio virtual microphone in CI
PulseAudio supports a module-null-sink that creates a virtual audio output device with zero hardware. Combined with module-virtual-source, you get a virtual microphone that Chrome can legitimately capture from — it will capture silence, but it can initialize, which is all the test needs.
The challenge is that CI containers run as root, and PulseAudio's default autospawn mode refuses to run as root:
W: [pulseaudio] main.c: This program is not intended to be run as root
E: [pulseaudio] main.c: Failed to acquire autospawn lock
The second attempt used --system mode, but pactl then refused to connect because there was no D-Bus and no auth cookie file:
E: [pulseaudio] core-util.c: Failed to connect to /run/dbus/system_bus_socket
W: [pulseaudio] authkey.c: Failed to open cookie file '/var/run/pulse/cookie'
W: [pulseaudio] protocol-native.c: Denied access: invalid authentication data
The solution that finally worked: start PulseAudio with -n (skip the default config file entirely) and preload all modules inline at startup, including a native protocol socket with auth-anonymous=1:
- name: Run vision & voice test
env:
PUPPETEER_EXECUTABLE_PATH: /opt/chrome-linux64/chrome
PULSE_SERVER: unix:/var/run/pulse/native
run: |
Xvfb :99 -screen 0 1920x1080x24 &
# Install PulseAudio if not already in the image
which pulseaudio > /dev/null 2>&1 || \
(apt-get update -qq && apt-get install -y -qq --no-install-recommends pulseaudio pulseaudio-utils)
mkdir -p /var/run/pulse
# -n: skip system.pa (no D-Bus loads)
# Preload modules inline so no pactl load-module calls are needed
# auth-anonymous=1: pactl and Chrome connect without a cookie
pulseaudio --system --disallow-exit --exit-idle-time=-1 -n \
--load="module-null-sink sink_name=fakesink sink_properties=device.description=VirtualSink" \
--load="module-virtual-source master=fakesink.monitor source_name=fakemic source_properties=device.description=VirtualMic" \
--load="module-native-protocol-unix auth-anonymous=1 socket=/var/run/pulse/native" \
--daemonize=true
sleep 1
pactl set-default-source fakemic
pactl set-default-sink fakesink
sleep 1
node tests/vision-voice-quick.test.js --extension-path=dist/extension/dev --skip-build
The flags break down as follows:
| Flag | Purpose |
|---|---|
--system |
Required when running as root; enables system-wide daemon mode |
-n |
Skip system.pa; avoids loading D-Bus-dependent modules that don't exist in Docker |
--load="module-null-sink ..." |
Create a virtual audio sink (output device) with no hardware |
--load="module-virtual-source ..." |
Create a virtual microphone that captures the sink's monitor stream |
--load="module-native-protocol-unix auth-anonymous=1 ..." |
Expose a UNIX socket that accepts connections without an auth cookie |
--daemonize=true |
Background the process cleanly |
PULSE_SERVER=unix:/var/run/pulse/native |
Tell both pactl and Chrome where to find the socket |
With this setup, Chrome's SpeechRecognition can initialize. The CI test output changed from:
SKIP: Known headless/environment limitation: "audio-capture"
to:
Voice after click: aria-pressed=true, aria-label=Stop voice input
Has "Listening" text: true
PASS: Voice button entered listening state with no errors
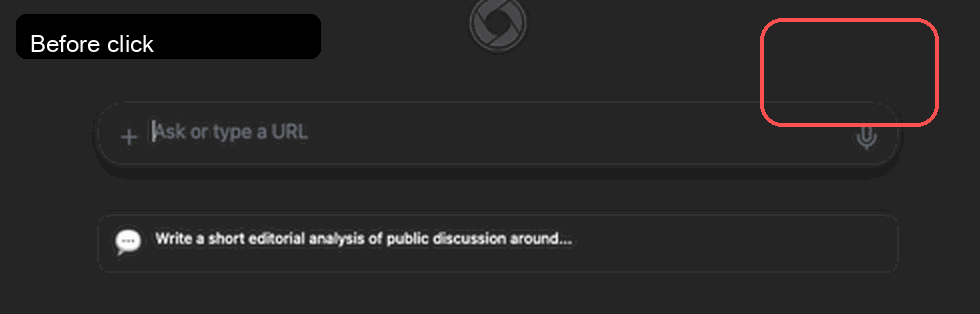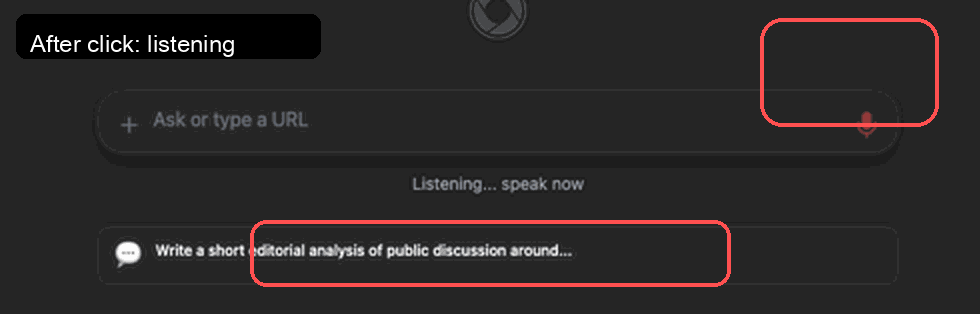
Updated CI proof GIF from the automated voice-eval run. It shows the complete side-by-side flow: sidepanel ready, microphone active, voice command transcribed into the input, task submission, and final assistant answer. This complements the log assertions by providing visual evidence of the runtime path.
The full three-tier defence
The complete guard against voice regressions now has three independent layers:
| Tier | Mechanism | Catches |
|---|---|---|
| 1 — Static | scripts/audit-manifest-permissions.js in lint |
Missing audioCapture before code ships |
| 2 — Strict test logic | isPermissionDeniedError → hard FAIL |
Runtime permission denial after any manifest change |
| 3 — Real audio pipeline | PulseAudio virtual mic in CI | SpeechRecognition initialization, button state, UI transitions |
Each tier catches something the others cannot. Static analysis is instant but can only check declarations, not runtime behaviour. Strict test assertions catch permission regressions but can't validate that the start() call succeeds. Only a real audio device validates that Chrome's internal audio capturer initialises cleanly.
Engineering values behind the setup
Tests should fail for the right reason. A green check is only useful if failure semantics are strict. Treating a permission regression as a SKIP keeps the dashboard green while the product is broken.
Separate product regressions from environment limitations. FAIL and SKIP mean different things operationally. Mixing them destroys the signal.
Use the cheapest check that can catch the class of bug. Static manifest audits are faster and more reliable than end-to-end tests for configuration regressions. End-to-end tests should be reserved for runtime boundaries that static analysis cannot validate.
For critical browser APIs, prefer real subsystem validation over mocks. Mocks are still useful, but they should not be the only proof that a microphone-dependent feature works.
Lessons
--use-fake-device-for-media-stream does not fake everything. It covers getUserMedia and WebRTC. Chrome's SpeechRecognition uses a different internal pathway that still needs a real OS audio device. If you are testing voice in a Chrome extension, you need PulseAudio or a kernel ALSA loopback.
Treating known errors as passing conditions is a trap. It is tempting to write if (error) { skip() } to keep CI green in constrained environments. The right pattern is to distinguish environment limitations (SKIP) from permission regressions (FAIL) explicitly, not fold both into a single "not our problem" bucket.
Static permission audits are worth the maintenance cost. A small Node script that exits 1 when a Chrome API is used without the corresponding manifest permission covers an entire class of silent breakage.
PulseAudio -n + inline module loads is the reliable pattern for root Docker containers. Skip the default config, preload what you need, and use anonymous auth when you control the isolated CI environment.
The result is a test that exercises the browser boundary we actually care about. It is more work than a mock, but it produces signal instead of comfort.